openflow switch(I)
一、基础概念图:
首先我们先看下Open Flow Switch的整体结构,以便有一个初步的感性认识,如下图所示:

从上面架构图中,我们可以看到Open Flow Switch主要是由以下几个部分构成:
1、Remote Controller:我们知道,SDN网络将传统的网络结构划分成了Control Plane和Data Plane两部分,这里的Remote Controller正是Control Plane部分,通过约定的通信协议来远程控制管理OpenFlow Switch,增加、删除或者修改OpenFlow Switch的Flow Entries。
2、OpenFlow Channel:它可以被认为是OpenFlow Switch对外开放的接口,接受来自于Remote Controller的通信协议,进而来操纵OpenFlow Switch。
3、OpenFlow Protocol:一种通信协议规范,用于Remote Controller和OpenFlow Switch之间的消息交换。
4、Flow Table:包含多个Flow Entry记录,控制数据包的流向,具体过程可参考下文。
5、Group Table:相对于Flow Table,控制着数据包更高级的转发特性,比如Flooding、Multipath、Fast Reroute、Link Aggregation等。
6、Pipeline:由多个Flow Table链接而成,控制数据包的一系列行为。
OpenFlow Ports
1、Standard Ports(标准端口):
OpenFlow Standard Ports通常被定义为是Physical ports, logical ports和支持的LOCAL Reserved ports(不包括其他的Reserved ports)。它们可被用于 ingress port,也可被用于 output port,同样可以用于 Group 里,它们都有 port counters。
2、Physical Ports(物理端口):
OpenFlow Physical Ports是OpenFlow Switch定义的、对应于物理交换机的一个硬件接口的port。比如在一个以太网交换机上,Physical Port会唯一对应于一个以太网接口。但是在一些特殊的环境中,比如在基于物理机硬件交换机上虚拟出来的OpenFlow Switch,它的Physical Port可能仅仅只是对应于这个物理硬件交换机的硬件接口上的一个虚拟切片。
3、Logical Ports(逻辑端口):
OpenFlow Logical Ports是OpenFlow Switch定义的端口,它并不直接对应物理交换机的硬件接口。Logical Ports是Switch中用non-OpenFlow methods(比如link aggregation groups, tunnels, loopback interfaces)定义的更高级别的抽象,它可能包括了对Packet的封装,可能会被映射到多种Physical Ports上。它们对Packet的处理对于OpenFlow processing来说一定要是透明的,而且Logical Ports必须得像Physical Ports一样与OpenFlow processing交互。
4、Reserved ports(预留端口):
OpenFlow Reserved ports是OpenFlow Switch规范定义的,它们指定了一些通用的转发动作,比如发送到Remote Controller, flooding, 用non-OpenFlow methods转发(或者说是“正常的”交换机处理)。一个OpenFlow Switch并不需要实现所有的Reserved Ports,但是必须得实现下面加黑表示的Reserved Ports:
1)ALL:表示那些所有能被Switch用来发送特定Packets的ports,其仅仅只能被作为一个output port;在这种情况下,Packet的一个拷贝将会被发送到所有的Standard Ports,除了Packet的 ingress port以及那些配置为OFPPC_NO_FWD的ports。Represents all ports the switch can use for forwarding a specific packet. Can be used only as an output port. In that case a copy of the packet starts egress processing on all
standard ports, excluding the packet ingress port and ports that are configured OFPPC_NO_FWD.
2)CONTROLLER:表示与Remote Controller之间的OpenFlow Channel,可以被用作为一个 ingress port,也可以被用作为一个 output port。当被用作为一个 output port时,Packet将会被封装在 packet-in 消息体里,并被以OpenFlow Protocol的方式发送给Remote Controller;当被作为一个 ingress port时,则表明该Packet来源于Remote Controller。
3)TABLE:代表OpenFlow Pipeline的开始,该port仅仅只能在一个 packet-out 消息的action集合中的 action是 output 时才有效,它将Packet发给OpenFlow Pipeline的第一个Flow Table,以便开始进行常规 processing。
4)IN_PORT:代表Packet的 ingress port,仅仅被用作为一个 output port,将Packet通过它的 ingress port发送出去。
5)ANY:特殊的值,用在没有指定port(或者port是通配的)的特殊OpenFlow Commands情况下;它即不能作为一个 ingress port,也不能作为一个 output port。
6)LOCAL:表示Switch本地网络栈和管理栈,可以被用作是一个 ingress port 或者是 output port。Local Ports能够使远程实体通过OpenFlow网络与Switch及其它的网络服务交互,而不用通过一个独立的控制网络。通过合适的默认Flow Entries集合,它可以被用来实现一个 in-band controller连接。
7)NORMAL:表示Switch传统的non-OpenFlow Pipeline,仅仅只能用作一个output port,且仅仅只能使用Normal Pipeline来处理Packets。如果该Switch并不能将来自于OpenFlow Pipeline的Packets转发给Normal Pipeline,那么必须得表明其不支持该action。
8)FLOOD:表示使用Switch Normal Pipeline的flooding,仅仅只能被用作为一个output port,通常通过它可以将Packets发到所有的Standard Ports上,但除了接收这个Packet的 ingress port 以及那些状态为OFPPS_BLOCKED的ports;当然,Switch也可能会根据Packet的VLAN ID来选择往哪些port去flood。
FLOOD: Represents flooding using the traditional non-OpenFlow pipeline of the switch(see 5.1). Can be used only as an output port, actual result is implementation dependant. In
general will send the packet out all standard ports, but not to the ingress port, nor ports that are
in OFPPS_BLOCKED state. The switch may also use the packet VLAN ID or other criteria to select
which ports to use for flooding.
OpenFlow-only Switches并不支持NORMAL和FLOOD端口,而OpenFlow-hybrid Switches可能会支持它们。将Packet转发到FLOOD port则依赖于Switch的实现和配置,而使用类型为all的组转发则能够使Remote Controller更加灵活地实现flooding。
Flow Tables
1、Pipeline Processing
遵循OpenFlow Switch规范的OpenFlow交换机大致分为 OpenFlow-only 和 OpenFlow-hybrid 两类。OpenFlow-only 交换机仅仅只支持OpenFlow规范定义的操作,所有经过该类交换机的数据包仅仅只能被 OpenFlow Pipeline 处理,而不能被其他方式处理。而 OpenFlow-hybrid 交换机既支持OpenFlow规范定义的操作,又支持传统交换机规定的操作,比如传统的L2交换、VLAN隔离、L3路由、ACL以及QoS处理等。该类交换机必须要提供一种除OpenFlow Switch规范约定的能将经过它的数据包转发到OpenFlow Pipeline处理,也能转发到Normal Pipeline处理特性之外的分类机制,比如交换机可以根据数据包的VLAN tag或者ingress port来决定使用某个Pipeline来处理,或者可能将所有的数据包直接转发到OpenFlow Pipeline处理。OpenFlow-hybrid 交换机也可能将来自于 OpenFlow Pipeline 处理后的数据包通过 NORMAL 或者 FLOOD Reserved Port 转发到 Normal Pipeline 继续处理。

OpenFlow Pipeline由多个Flow Tables组成,而每个Flow Table又包含有多个Flow Entries。Pipeline Processing定义了数据包如何与这些Flow Tables进行交互,一个OpenFlow Switch至少得有一个Flow Table,或者有多个。当Pipeline有多个Flow Tables时,这些Flow Tables是按照数字顺序排列的,起始索引号从 0 开始,任何进入到OpenFlow Switch的数据包都会从Pipeline的第一个Flow Table,即 Table 0 开始处理,后续的Flow Table可能会被使用到,而这依赖于Table 0中匹配成功的Flow Entry的输出结果。

2、Flow Tables and flow entries
A flow table consists of flow entries.

Each flow table entry (see Table 1) contains :
• match fields: to match against packets. These consist of the ingress port and packet headers, and optionally other pipeline fields such as metadata specified by a previous table.
• priority: matching precedence of the flow entry.
• counters: updated when packets are matched.
• instructions: to modify the action set or pipeline processing.
• timeouts: maximum amount of time or idle time before flow is expired by the switch.
• cookie: opaque data value chosen by the controller. May be used by the controller to filter flow entries affected by flow statistics, flow modification and flow deletion requests. Not used when processing packets.
• flags: flags alter the way flow entries are managed, for example the flag OFPFF_SEND_FLOW_REM triggers flow removed messages for that flow entry.
一个Flow Entry在Flow Table中通过Match Fields和Priority两个字段来唯一标识(或称为联合主键)。
5.3 Matching
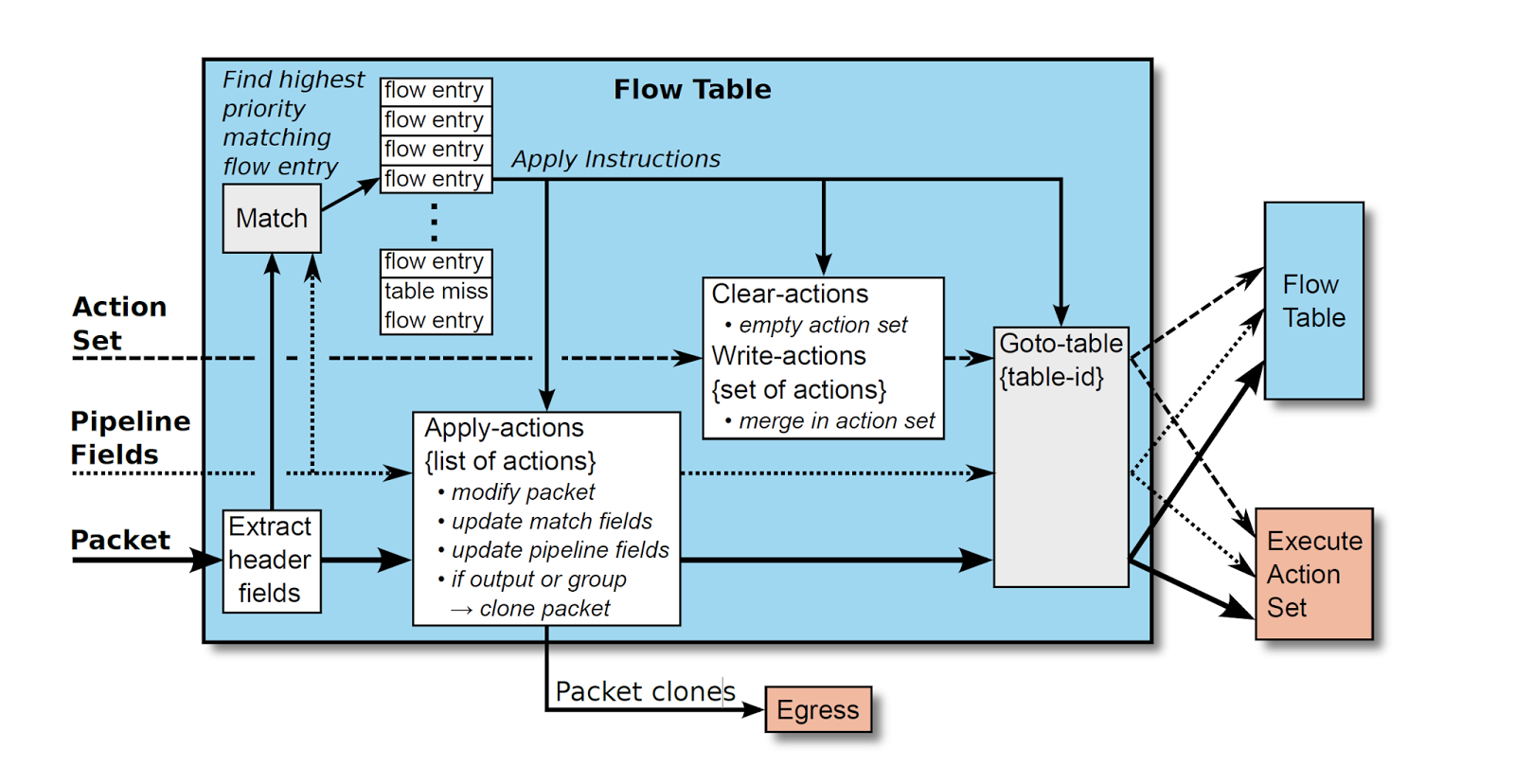
当一个来自于外部网络的数据包进入到OpenFlow Switch中时,OpenFlow Switch将会按照如下图所示的方式来处理这些数据包,如前面的学习笔记中讲述的那样,会先从Pipeline的第一个Flow Table首先进行Lookup,然后可能继续进入到其他的Flow Table进行Lookup。匹配过程图如下:

数据包的匹配值域来源于数据包头,这些匹配值域将会依据数据包的类型被用来与Flow Table进行匹配,比如源地址或者目标地址;另外,除了数据包头信息外,数据包的 ingress port 或者 从上一个Flow Table传递过来的 Metadata 值域(在Flow Table之间进行参数传递的载体)也可以充当匹配域。数据包的匹配值域表示了数据包当前的状态值,假若数据包在前一个Flow Table里应用了Apply Actions改变了数据包头信息,那么这么改变将会被立即反映到数据包头信息里。
数据包与某个Flow Entry能成功匹配的前提是:数据包的匹配值域都必须落在Flow Entry匹配值域的范围内。假若一个Flow Entry的匹配值域是ANY,那么它将表示匹配数据包的所有可能的值域信息。当发现有多个Flow Entries匹配成功,那么仅仅具有最高优先权的Flow Entry将会被选择使用,同时该Flow Entry的Counters的值必须被更新。如果OpenFlow Switch配置了OFPC_FRAG_REASM,那么在进行Pipeline processing的时候,IP片段必须要被重组起来。OpenFlow Switch规范并没有定义当遇到格式不正确的或者损坏的数据包时该如何处理。
2、Table Miss
如前面的学习笔记记录那样,每个Flow Table都必须支持Table Miss Flow Entry,用来处理当发生Table Miss 时如何处理数据包,或者将其发送回Remote Controller,或者将其直接丢弃,或者将其转发到后续的Flow Table里处理。
如同其他正常的Flow Entry一样,Table Miss Flow Entry也是由Match Fields和Prioriy作为联合主健来唯一定位,它能够匹配所有的数据包值域,即能够匹配的值域范围要超出Flow Table的正常范围,并且拥有最低的优先级 0 ,但是其可能没有其他正常Flow Entry的能力。然而,Table Miss Flow Entry必须至少得能够通过CONTROLLER Reserved Port将数据包发送给Remote Controller,以及通过Clear-Actions直接丢弃数据包,但是为了与前面规范保持一致,推荐直接将数据包转发给后续的Flow Table处理。
Table Miss Flow Entry的工作方式与其他正常的Flow Enety无异,默认情况下,Flow Table里并不存在Table Miss Flow Entry,但是在任何时候都可以通过Remote Controller来添加或者删除,它也如同其他正常Flow Entry可能会过期。它仅仅匹配其他正常Flow Entry无法成功匹配的数据包,并且其上得Instructions Set将会应用到数据包上。当经过Table Miss Flow Entry的Actions通过CONTROLLER Reserved Port将数据包发送给Remote Controller时,必须指明packet-in消息的原因是table miss。
如果一个Flow Table并不存在Table Miss Flow Entry,那么其未能成功匹配的数据包就会被丢弃,但是基于不同的OpenFlow Switch实现策略,可以覆盖其默认行为,以其他的方式来实现。
Group Table、Meter Table及Counters
1、Group Table

A group table consists of group entries. The ability for a flow entry to point to a group enables OpenFlow to represent additional methods of forwarding (e.g. select and all).Each group entry (see Table 6) is identified by its group identifier and contains:
• group identifier: a 32 bit unsigned integer uniquely identifying the group on the OpenFlow switch.
• group type: to determine group semantics (see Section 5.10.1).
• counters: updated when packets are processed by a group.
• action buckets: an ordered list of action buckets, where each action bucket contains a set of actions to execute and associated parameters. The actions in a bucket are always applied as an action set (see 5.6).
Group Types
5.10.1 Group Types
1)all:Group Table中所有的Action Buckets都会被执行,这种类型的Group Table主要用于数据包的多播或者广播。数据包对于每一个Action Bucket都会被克隆一份,进而克隆体被处理。如果一个Action Bucket显示地将数据包发回其 ingress port,那么该数据包克隆体会被丢弃;但是,如果确实需要将数据包的一个克隆体发送回其 ingress port,那么该Group Table里就需要一个额外的Action Bucket,它包含了一个 output action 将数据包发送到 OFPP_IN_PORT Reserved Port。
2)select:仅仅执行Group Table中的某一个Action Bucket,基于OpenFlow Switch的调度算法,比如基于用户某个配置项的hash或者简单的round robin,所有的配置信息对于OpenFlow Switch来说都是属于外部的。当将数据包发往一个当前down掉的port时,Switch能将该数据包替代地发送给一个预留集合(能将数据包转发到当前live的ports上),而不是毫无顾忌地继续将数据包发送给这个down的port,这或许可以明显降低由于一个down的link或者switch带来的灾难。
3)indirect:执行Group Table中已经定义好的Action Bucket,这种类型的Group Table仅仅只支持一个Action Bucket。允许多个Flow Entries或者Groups 指向同一个通用的 Group Identifier,支持更快更高效的聚合。这种类型的Group Table与那些仅有一个Action Bucket的Group Table是一样的。
4)fast failover:执行第一个live的Action Bucket,每一个Action Bucket都关联了一个指定的port或者group来控制它的存活状态。Buckets会依照Group顺序依次被评估,并且第一个关联了一个live的port或者group的Action Bucket会被筛选出来。这种Group类型能够自行改变Switch的转发行为而不用事先请求Remote Controller。如果当前没有Buckets是live的,那么数据包就被丢弃,因此这种Group必须要实现一个管理存活状态的机制。
1)all:Group Table中所有的Action Buckets都会被执行,这种类型的Group Table主要用于数据包的多播或者广播。数据包对于每一个Action Bucket都会被克隆一份,进而克隆体被处理。如果一个Action Bucket显示地将数据包发回其 ingress port,那么该数据包克隆体会被丢弃;但是,如果确实需要将数据包的一个克隆体发送回其 ingress port,那么该Group Table里就需要一个额外的Action Bucket,它包含了一个 output action 将数据包发送到 OFPP_IN_PORT Reserved Port。
2)select:仅仅执行Group Table中的某一个Action Bucket,基于OpenFlow Switch的调度算法,比如基于用户某个配置项的hash或者简单的round robin,所有的配置信息对于OpenFlow Switch来说都是属于外部的。当将数据包发往一个当前down掉的port时,Switch能将该数据包替代地发送给一个预留集合(能将数据包转发到当前live的ports上),而不是毫无顾忌地继续将数据包发送给这个down的port,这或许可以明显降低由于一个down的link或者switch带来的灾难。
3)indirect:执行Group Table中已经定义好的Action Bucket,这种类型的Group Table仅仅只支持一个Action Bucket。允许多个Flow Entries或者Groups 指向同一个通用的 Group Identifier,支持更快更高效的聚合。这种类型的Group Table与那些仅有一个Action Bucket的Group Table是一样的。
4)fast failover:执行第一个live的Action Bucket,每一个Action Bucket都关联了一个指定的port或者group来控制它的存活状态。Buckets会依照Group顺序依次被评估,并且第一个关联了一个live的port或者group的Action Bucket会被筛选出来。这种Group类型能够自行改变Switch的转发行为而不用事先请求Remote Controller。如果当前没有Buckets是live的,那么数据包就被丢弃,因此这种Group必须要实现一个管理存活状态的机制。

评论
发表评论